- Karthik Ragunath Ananda Kumar
I built a minimal state space model in pure PyTorch and trained it character-by-character on tiny-shakespeare dataset to understand how SSMs and Mamba actually work. This post walks through that code and explains what each piece does, why it’s there, and how it all fits together.
A language model takes a sequence of tokens and predicts the next one. Transformers do this with attention: every new token looks at every previous token via $\text{softmax}(QK^T)V$, which costs $O(N^2)$ for training and forces you to keep every previous K and V in memory during inference.
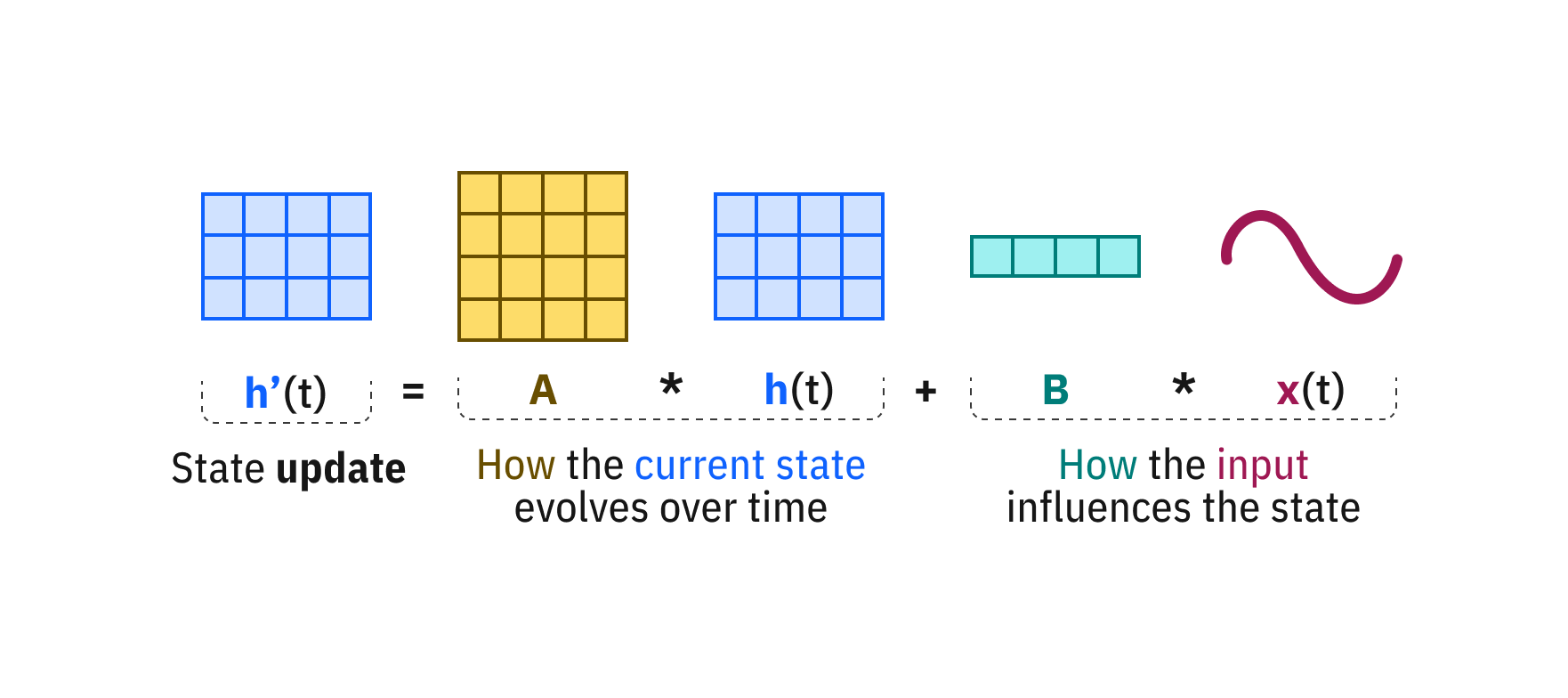
State Space Models (SSMs) take a different route. Instead of letting each token see every previous token directly, they compress the entire past into a small fixed-size hidden state and update that state one token at a time. Cost per token: $O(1)$. Memory: the hidden state, period. No cache that grows linearly with context.
Pure SSMs (S4, S5, H3) had this nice cost structure but couldn’t quite match transformer quality at scale. The reason was that their dynamics were “linear time-invariant”: the same recurrence applied to every token regardless of what the token was.
Take the recurrence $h_t = \bar{A} h_{t-1} + \bar{B} x_t$ with fixed $\bar{A} = 0.5$ and $\bar{B} = 1$. Three inputs arrive: $x_1 = 10$, $x_2 = 6$, $x_3 = 4$.
But look at where each piece of $h_3$ actually came from:
| Original input | How old is it? | How many times halved? | Contribution to $h_3$ |
|---|---|---|---|
| $x_1 = 10$ | 2 steps ago | $0.5^2 = 0.25$ | $0.25 \times 10 = 2.5$ |
| $x_2 = 6$ | 1 step ago | $0.5^1 = 0.5$ | $0.5 \times 6 = 3.0$ |
| $x_3 = 4$ | just arrived | $0.5^0 = 1$ | $1 \times 4 = 4.0$ |
| total | $2.5 + 3.0 + 4.0 = 9.5$ |
Every past input’s contribution follows the same rule: an input that arrived $k$ steps ago has been multiplied by $\bar{A}$ exactly $k$ times. Its weight is $\bar{A}^k \bar{B}$, regardless of what step we’re at. This weight schedule is the same everywhere in the sequence. It doesn’t matter if we’re computing $h_5$ or $h_{500}$. “Two steps ago” always means “multiplied by $\bar{A}$ twice,” because $\bar{A}$ is constant.
That’s basically a convolution: a fixed set of weights $(1.0, 0.5, 0.25, 0.125, \ldots)$ applied at every position. At position $t$ the output is $y_t = 1.0 \cdot x_t + 0.5 \cdot x_{t-1} + 0.25 \cdot x_{t-2} + \ldots$. Convolutions can be computed all at once (in parallel, or via FFT) without stepping through the sequence one position at a time. That’s the huge speed advantage of LTI: you never actually run the recurrence during training.
The problem is quality. The system can’t say “this is a content word, absorb it strongly” or “this is filler, ignore it.” Every token gets the same $\bar{A}$ and the same $\bar{B}$. It can’t selectively gate.